**Troubleshooting formula errors with Excel export:
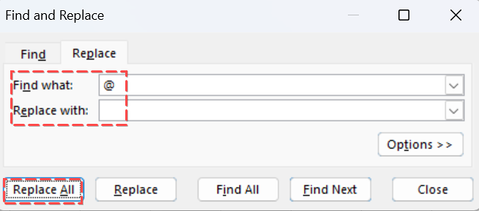
The @ symbol was introduced in Excel 365 (also known as Excel 2016 and later versions) as part of the dynamic array functionality. Therefore, some formulas exported to those Excel versions may be prefixed with @ and return a #NAME? error. This can be easily fixed by selecting the cell/ range that contains #NAME? error and using "Find & Replace" option in Excel (ctrl+F).
Supported Formulas in Reach Reporting:
Use CTRL + F to quickly find formulas.
| Formula | Definition | Syntax |
| ABS | Absolute value of a number. | ABS(value) |
| ACCRINT | Accrued interest of a security that has periodic payments. | ACCRINT(issue, first_payment, settlement, rate, redemption, frequency, [day_count_convention]) |
| ACOS | Inverse cosine of a value, in radians. | ACOS(value) |
| ACOSH | Inverse hyperbolic cosine of a number. | ACOSH(value) |
| ACOT | Inverse cotangent of a value, in radians. | ACOT(value) |
| ACOTH | Inverse hyperbolic cotangent of a value, in radians. | ACOTH(value) |
| AGGREGATE | Applies different aggregate functions to a list or database with the option to ignore hidden rows and error values. | AGGREGATE(function_num, options, array, [k]) |
| AND | Returns TRUE if all of the provided arguments are logically true, and FALSE if any of the provided arguments are logically false. | AND(logical_expression1, [logical_expression2, ...]) |
| ARABIC | Computes the value of a Roman numeral. | ARABIC(roman_numeral) |
| ASIN | Inverse sine of a value, in radians. | ASIN(value) |
| ASINH | Inverse hyperbolic sine of a number. | ASINH(value) |
| ATAN | Inverse tangent of a value, in radians. | ATAN(value) |
| ATANH | Inverse hyperbolic tangent of a number. | ATANH |
| AVEDEV | Average of the magnitudes of deviations of data from a dataset's mean. | AVEDEV(value1, [value2, ...]) |
| AVERAGE | Numerical average value in a dataset, ignoring text. | AVERAGE(value1, [value2, ...]) |
| AVERAGEA | Numerical average value in a dataset. | AVERAGEA(value1, [value2, ...]) |
| AVERAGEIF | Average of a range depending on criteria. | AVERAGEIF(criteria_range, criterion, [average_range]) |
| AVERAGEIFS | Average of a range depending on multiple criteria. | AVERAGEIFS(average_range, criteria_range1, criterion1, [criteria_range2, criterion2, ...]) |
| BASE | Converts a number into a text representation in another base, for example, base 2 for binary. | BASE(value, base, [min_length]) |
| BESSELI | Returns the modified Bessel function. | BESSELI(x, n) |
| BESSELJ | Returns the Bessel function. | BESSELJ(x, n) |
| BESSELK | Returns the modified Bessel function. | BESSELK(x, n) |
| BESSELY | Returns the Bessel function. | BESSELY(x, n) |
| BETA.DIST | Probability of a given value as defined by the beta distribution function. | BETA.DIST(value, alpha, beta, cumulative, lower_bound, upper_bound) |
| BETA.INV | Value of the inverse beta distribution function for a given probability. | BETA.INV(probability, alpha, beta, lower_bound, upper_bound) |
| BIN2DEC | Converts a signed binary number to decimal format. | BIN2DEC(signed_binary_number) |
| BIN2HEX | Converts a signed binary number to signed hexadecimal format. | BIN2HEX(signed_binary_number, [significant_digits]) |
| BIN2OCT | Converts a signed binary number to signed octal format. | BIN2OCT(signed_binary_number, [significant_digits]) |
| BINOM.DIST | Calculates the probability of drawing a certain number of successes (or a maximum number of successes) in a certain number of tries given a population of a certain size containing a certain number of successes, with replacement of draws. | BINOM.DIST(num_successes, num_trials, prob_success, cumulative) |
| BINOM.DIST.RANGE | Returns the probability of a trial result using a binomial distribution. | BINOM.DIST.RANGE(num_trials, prob_success,number_s,[number_s2]) |
| BINOM.INV | Calculates the smallest value for which the cumulative binomial distribution is greater than or equal to a specified criteria. | BINOM.INV(num_trials, prob_success, target_prob) |
| BITAND | Bitwise boolean AND of two numbers. | BITAND(value1, value2) |
| BITLSHIFT | Shifts the bits of the input a certain number of places to the left. | BITLSHIFT(value, shift_amount) |
| BITOR | Bitwise boolean OR of 2 numbers. | BITOR(value1, value2) |
| BITRSHIFT | Shifts the bits of the input a certain number of places to the right. | BITRSHIFT(value, shift_amount) |
| BITXOR | Bitwise XOR (exclusive OR) of 2 numbers. | BITXOR(value1, value2) |
| CEILING | Rounds a number up to the nearest integer multiple of specified significance. | CEILING(value, [factor]) |
| CEILING.MATH | Rounds a number up to the nearest integer multiple of specified significance, with negative numbers rounding toward or away from 0 depending on the mode. | CEILING.MATH(number, [significance], [mode]) |
| CHAR | Convert a number into a character according to the current Unicode table. | CHAR(table_number) |
| CHISQ.DIST | Calculates the left-tailed chi-squared distribution, often used in hypothesis testing. | CHISQ.DIST(x, degrees_freedom, cumulative) |
| CHISQ.DIST.RT | Calculates the right-tailed chi-squared distribution, which is commonly used in hypothesis testing. | CHISQ.DIST.RT(x, degrees_freedom) |
| CHISQ.INV | Calculates the inverse of the left-tailed chi-squared distribution. | CHISQ.INV(probability, degrees_freedom) |
| CHISQ.INV.RT | Calculates the inverse of the right-tailed chi-squared distribution. | CHISQ.INV.RT(probability, degrees_freedom) |
| CHOOSE | Returns an element from a list of choices based on index. | CHOOSE(index, choice1, [choice2, ...]) |
| CODE | Returns the numeric Unicode map value of the first character in the string provided. | CODE(string) |
| COLUMNS | Returns the number of columns in a specified array or range. | COLUMN([cell_reference]) |
| COMBIN | Returns the number of ways to choose some number of objects from a pool of a given size of objects. | COMBIN(n, k) |
| COMBINA | Returns the number of ways to choose some number of objects from a pool of a given size of objects, including ways that choose the same object multiple times. | COMBINA(n, k) |
| COMPLEX | Creates a complex number given real and imaginary coefficients. | COMPLEX(real_part, imaginary_part, [suffix]) |
| CONCATENATE | Appends strings to one another. | CONCATENATE(string1, [string2, ...]) |
| CONFIDENCE.NORM | Calculates the width of half the confidence interval for a normal distribution. | CONFIDENCE.NORM(alpha, standard_deviation, pop_size) |
| CONFIDENCE.T | Calculates the width of half the confidence interval for a Student’s t-distribution. | CONFIDENCE.T(alpha, standard_deviation, size) |
| CORREL | Calculates r, the Pearson product-moment correlation coefficient of a dataset. | CORREL(data_y, data_x) |
| COS | Cosine of an angle provided in radians. | COS(angle) |
| COSH | Hyperbolic cosine of any real number. | COSH(value) |
| COT | Cotangent of an angle provided in radians. | COT(angle) |
| COTH | Hyperbolic cotangent of any real number. | COTH(value) |
| COUNT | Count of the number of numeric values in a dataset. | COUNT(value1, [value2, ...]) |
| COUNTA | Count of the number of values in a dataset. | COUNTA(value1, [value2, ...]) |
| COUNTBLANK | The number of empty cells in a given range. | COUNTBLANK(range) |
| COUNTIF | Returns a conditional count across a range. | COUNTIF(range, criterion) |
| COUNTIFS | Returns the count of a range depending on multiple criteria. | COUNTIFS(criteria_range1, criterion1, [criteria_range2, criterion2, ...]) |
| COVARIANCE.P | Calculates the covariance of a dataset. | COVARIANCE.P(data_y, data_x) |
| COVARIANCE.S | Calculates the covariance of a dataset, where the dataset is a sample of the total population. | COVARIANCE.S(data_y, data_x) |
| CSC | the cosecant of an angle provided in radians. | CSC(angle) |
| CSCH | he hyperbolic cosecant of any real number. | CSCH(value) |
| CUMIPMT | Cumulative interest over a range of payment periods for an investment based on constant-amount periodic payments and a constant interest rate. | CUMIPMT(rate, number_of_periods, present_value, first_period, last_period, end_or_beginning) |
| CUMPRINC | Cumulative principal paid over a range of payment periods for an investment based on constant-amount periodic payments and a constant interest rate. | CUMPRINC(rate, number_of_periods, present_value, first_period, last_period, end_or_beginning) |
| DATE | Converts a provided year, month, and day into a date. | DATE(year, month, day) |
| DATEVALUE | Converts a provided date string in a known format to a date value. | DATEVALUE(date_string) |
| DAY | Day of the month that a specific date falls on, in numeric format. | DAY(date) |
| DAYS | Returns the number of days between two dates. | DAYS(end_date, start_date) |
| DAYS360 | Returns the difference between two days based on the 360 day year used in some financial interest calculations. | DAYS360(start_date, end_date, [method]) |
| DB | Calculates the depreciation of an asset for a specified period using the arithmetic declining balance method. | DB(cost, salvage, life, period, [month]) |
| DDB | Calculates the depreciation of an asset for a specified period using the double-declining balance method. | DDB(cost, salvage, life, period, [factor]) |
| DEC2BIN | Converts a decimal number to signed binary format. | DEC2BIN(decimal_number, [significant_digits]) |
| DEC2HEX | Converts a decimal number to signed hexadecimal format. | DEC2HEX(decimal_number, [significant_digits]) |
| DEC2OCT | Converts a decimal number to signed octal format. | DEC2OCT(decimal_number, [significant_digits]) |
| DECIMAL | Converts the text representation of a number in another base, to base 10 (decimal). | DECIMAL(value, base) |
| DEGREES | Converts an angle value in radians to degrees. | DEGREES(angle) |
| DELTA | Compare two numeric values, returning 1 if they're equal and 0 otherwise. | DELTA(number1, [number2]) |
| DEVSQ | Calculates the sum of squares of deviations based on a sample. | DEVSQ(value1, value2) |
| DOLLARDE | Converts a price quotation given as a decimal fraction into a decimal value. | DOLLARDE(fractional_price, unit) |
| DOLLARFR | Converts a price quotation given as a decimal fraction into a decimal value. | DOLLARFR(decimal_price, unit) |
| EDATE | Returns a date a specified number of months before or after another date. | EDATE(start_date, months) |
| EFFECT | Calculates the annual effective interest rate given the nominal rate and number of compounding periods per year. | EFFECT(nominal_rate, periods_per_year) |
| EOMONTH | Returns a date representing the last day of a month which falls a specified number of months before or after another date. | EOMONTH(start_date, months |
| ERFC | The complementary Gauss error function of a value. | ERFC(z) |
| EVEN | Rounds a number up to the nearest even integer. | EVEN(value) |
| EXACT | Tests whether two strings are identical. Returns TRUE if true and FALSE otherwise. | EXACT(string1, string2) |
| EXP | Returns Euler's number, e (~2.718) raised to a power. | EXP(exponent) |
| EXPON.DIST | Returns the value of the exponential distribution function with a specified LAMBDA at a specified value. | EXPON.DIST(x, LAMBDA, cumulative) |
| F.DIST | Calculates the left-tailed F probability distribution (degree of diversity) for two data sets with given input x. Alternately called Fisher-Snedecor distribution or Snedecor's F distribution | F.DIST(x, degrees_freedom1, degrees_freedom2, cumulative) |
| F.DIST.RT | Calculates the right-tailed F probability distribution (degree of diversity) for two data sets with given input x. Alternately called Fisher-Snedecor distribution or Snedecor's F distribution. | F.DIST.RT(x, degrees_freedom1, degrees_freedom2) |
| F.INV | The inverse of the left-tailed F probability distribution. Also called the Fisher-Snedecor distribution or Snedecor’s F distribution. | F.INV(probability, degrees_freedom1, degrees_freedom2) |
| F.INV.RT | The inverse of the right-tailed F probability distribution. Also called the Fisher-Snedecor distribution or Snedecor’s F distribution. | F.INV.RT(probability, degrees_freedom1, degrees_freedom2) |
| FACT | Returns the factorial of a number. | FACT(value) |
| FACTDOUBLE | Returns the "double factorial" of a number. | FACTDOUBLE(value) |
| FALSE | Returns the logical value `FALSE`as FALSE. | FALSE() |
| FIND | Returns the position at which a string is first found within text. | FIND(search_for, text_to_search, [starting_at]) |
| FISHER | Returns the Fisher transformation of a specified value. | FISHER(value) |
| FISHERINV | Returns the inverse Fisher transformation of a specified value. | FISHERINV(value) |
| FLOOR | Rounds a number down to the nearest integer multiple of specified significance/ factor. | FLOOR(value, [factor]) |
| FORECAST | Calculates the expected y-value for a specified x based on a linear regression of a dataset. | FORECAST(x, data_y, data_x) |
| FV | The future value of an annuity investment based on constant-amount periodic payments and a constant interest rate. | FV(rate, number_of_periods, payment_amount, [present_value], [end_or_beginning]) |
| GAMMA | Returns the Gamma function evaluated at the specified value. | GAMMA(number) |
| GAMMA.DIST | Calculates the gamma distribution, a two-parameter continuous probability distribution. | GAMMA.DIST(x, alpha, beta, cumulative) |
| GAMMA.INV | Returns the value of the inverse gamma cumulative distribution function for the specified probability and alpha and beta parameters. | GAMMA.INV(probability, alpha, beta) |
| GAMMALN.PRECISE | The logarithm of a specified Gamma function, base e (Euler's number). | GAMMALN.PRECISE(value) |
| GAUSS | The probability that a random variable, drawn from a normal distribution, will be between the mean and z standard deviations above (or below) the mean. | GAUSS(z) |
| GCD | Returns the greatest common divisor of one or more integers. | GCD(value1, value2) |
| GEOMEAN | Calculates the geometric mean of a dataset. | GEOMEAN(value1, value2) |
| GESTEP | Returns TRUE if the rate is strictly greater than or equal to the provided step value or FALSE otherwise. If no step value is provided then the default value of 0 will be used. | GESTEP(value, [step]) |
| HARMEAN | Calculates the harmonic mean of a dataset. | HARMEAN(value1, value2) |
| HYPGEOM.DIST | The probability of drawing a certain number of successes in a certain number of tries given a population of a certain size containing a certain number of successes, without replacement of draws. | HYPGEOM.DIST(num_successes, num_draws, successes_in_pop, pop_size, cumulative) |
| IF | Returns one value if a logical expression is `TRUE` and another if it is `FALSE`. | IF(logical_expression, value_if_true, value_if_false) |
| IFERROR | Returns the first argument if it is not an error value, otherwise returns the second argument if present, or a blank if the second argument is absent. | IFERROR(value, [value_if_error]) |
| IMABS | Returns absolute value of a complex number. | IMABS(number) |
| IMAGINARY | Returns the imaginary coefficient of a complex number. | IMAGINARY(complex_number) |
| IMARGUMENT | Returns the angle (also known as the argument or \theta) of the given complex number in radians. | IMARGUMENT(number) |
| IMCONJUGATE | Returns the complex conjugate of a number. | IMCONJUGATE(number) |
| IMCOS | returns the cosine of the given complex number. | IMCOS(number) |
| IMCOSH | Returns the hyperbolic cosine of the given complex number. For example, a given complex number "x+yi" returns "cosh(x+yi)." | IMCOSH(number) |
| IMCOT | Returns the cotangent of the given complex number. For example, a given complex number "x+yi" returns "cot(x+yi)." | IMCOT(number) |
| IMCSC | Returns the cosecant of the given complex number. | IMCSC(number) |
| IMCSCH | Returns the hyperbolic cosecant of the given complex number. For example, a given complex number "x+yi" returns "csch(x+yi)." | IMCSCH(number) |
| IMDIV | Returns one complex number divided by another. | IMDIV(dividend, divisor) |
| IMEXP | Returns Euler's number, e (~2.718) raised to a complex power. | IMEXP(exponent) |
| IMLN | Returns the logarithm of a complex number, base e (Euler's number). | IMLN(complex_value) |
| IMPOWER | Returns a complex number raised to a power. | IMPOWER(complex_base, exponent) |
| IMPRODUCT | Returns the result of multiplying a series of complex numbers together. | IMPRODUCT(factor1, [factor2, ...]) |
| IMREAL | Returns the real coefficient of a complex number. | IMREAL(complex_number) |
| IMSEC | Returns the secant of the given complex number. For example, a given complex number "x+yi" returns "sec(x+yi)." | IMSEC(number) |
| IMSECH | Returns the hyperbolic secant of the given complex number. For example, a given complex number "x+yi" returns "sech(x+yi)." | IMSECH(number) |
| IMSIN | Returns the sine of the given complex number. | IMSIN (number) |
| IMSINH | Returns the hyperbolic sine of the given complex number. For example, a given complex number "x+yi" returns "sinh(x+yi)." | IMSINH(number) |
| IMSQRT | Computes the square root of a complex number. | IMSQRT(complex_number) |
| IMSUB | Returns the difference between two complex numbers. | IMSUB(first_number, second_number) |
| IMSUM | Returns the sum of a series of complex numbers. | IMSUM(value1, [value2, ...]) |
| IMTAN | Returns the tangent of the given complex number. | IMTAN(number) |
| INT | Rounds a number down to the nearest integer that is less than or equal to it. | INT(value) |
| INTERCEPT | Calculates the y-value at which the line resulting from linear regression of a dataset will intersect the y-axis (x=0). | INTERCEPT(data_y, data_x) |
| IPMT | Calculates the payment on interest for an investment based on constant-amount periodic payments and a constant interest rate. | IPMT(rate, period, number_of_periods, present_value, [future_value], [end_or_beginning]) |
| IRR | Calculates the internal rate of return on an investment based on a series of periodic cash flows. | IRR(cashflow_amounts, [rate_guess]) |
| ISEVEN | Checks whether the provided value is even. Returns TRUE if true and FALSE otherwise. | ISEVEN(value) |
| ISNONTEXT | Checks whether a value is non-textual. Returns FALSE if a text value or a reference to a cell containing a text value and TRUE otherwise. | ISNONTEXT(value) |
| ISNUMBER | Checks whether a value is a number. Returns TRUE if a number or a reference to a cell containing a numeric value and FALSE otherwise. | ISNUMBER(value) |
| ISODD | Checks whether the provided value is odd. Returns TRUE if an odd integer or a reference to a cell containing an odd integer, and FALSE otherwise. | ISODD(value) |
| ISOWEEKNUM | Returns the number of the ISO week of the year where the provided date falls | ISOWEEKNUM(date) |
| ISPMT | The ISPMT function calculates the interest paid during a particular period of an investment. | ISPMT(rate, period, number_of_periods, present_value) |
| ISTEXT | Checks whether a value is text. Returns TRUE if a text value or a reference to a cell containing a text value and FALSE otherwise. | ISTEXT(value) |
| KURT | Calculates the kurtosis of a dataset, which describes the shape, and in particular the "peakedness" of that dataset. | KURT(value1, value2) |
| LARGE | Returns the nth largest element from a data set, where n is user-defined. | LARGE(data, n) |
| LCM | Returns the least common multiple of one or more integers. | LCM(value1, value2) |
| LEFT | Returns a substring from the beginning of a specified string. | LEFT(string, [number_of_characters]) |
| LEN | Returns the length of a text string | LEN(text) |
| LN | Returns the the logarithm of a number, base e (Euler's number). | LN(value) |
| LOG | Returns the the logarithm of a number given a base. | LOG(value, base) |
| LOG10 | Returns the the logarithm of a number, base 10. | LOG10(value) |
| LOGNORM.DIST | Returns the value of the log-normal cumulative distribution with given mean and standard deviation at a specified value. | LOGNORM.DIST(x, mean, standard_deviation, cumulative) |
| LOGNORM.INV | Returns the inverse value of the log-normal cumulative distribution with given mean and standard deviation at a specified value. | LOGNORM.INV(x, mean, standard_deviation) |
| LOWER | Converts a specified string to lowercase. | LOWER(text) |
| MATCH | Returns the relative position of an item in a range that matches a specified value. | MATCH(search_key, range, [search_type]) |
| MAX | Maximum value in a numeric dataset. | MAX(value1, [value2, ...]) |
| MAXA | Returns the maximum numeric value in a dataset. Does not ignore logical values and text. | MAXA(value1, value2) |
| MEDIAN | Returns the median value in a numeric dataset. | MEDIAN(value1, [value2, ...]) |
| MID | Returns a segment of a string. | MID(string, starting_at, extract_length) |
| MIN | Minimum value in a numeric dataset. | MIN(value1, [value2, ...]) |
| MINA | Returns the minimum numeric value in a dataset. Does not ignore logical values and text. | MINA(value1, value2) |
| MOD | Returns the result of the modulo operator, the remainder after a division operation. | MOD(dividend, divisor) |
| MODE.SNGL | Returns the most commonly occurring value in a dataset. | MODE.SNGL(value1, [value2, ...]) |
| MONTH | Returns the month of the year a specific date falls in, in numeric format. | MONTH(date) |
| MROUND | Rounds one number to the nearest integer multiple of another. | MROUND(value, factor) |
| MULTINOMIAL | Returns the factorial of the sum of values divided by the product of the values' factorials. | MULTINOMIAL(value1, value2) |
| NEGBINOM.DIST | Calculates the probability of drawing a certain number of failures before a certain number of successes given a probability of success in independent trials. | NEGBINOM.DIST(num_failures, num_successes, prob_success) |
| NETWORKDAYS | Returns the number of net working days between two provided days. | NETWORKDAYS(start_date, end_date, [holidays]) |
| NOMINAL | Calculates the annual nominal interest rate given the effective rate and number of compounding periods per year. | NOMINAL(effective_rate, periods_per_year) |
| NORM.DIST | Returns the value of the normal distribution function (or normal cumulative distribution function) for a specified value, mean, and standard deviation. | NORM.DIST(x, mean, standard_deviation, cumulative) |
| NORM.INV | Returns the value of the inverse normal distribution function for a specified value, mean, and standard deviation. | NORM.INV(x, mean, standard_deviation) |
| NORM.S.DIST | Returns the value of the standard normal cumulative distribution function for a specified value. | NORM.S.DIST(x, cumulative) |
| NORM.S.INV | Returns the value of the inverse standard normal distribution function for a specified value. | NORM.S.INV(x) |
| NOT | Returns the opposite of a logical value - `NOT(TRUE)` returns FALSE and `NOT(FALSE)` returns TRUE. | NOT(logical_expression) |
| NPER | Calculates the number of payment periods for an investment based on constant-amount periodic payments and a constant interest rate. | NPER(rate, payment_amount, present_value, [future_value], [end_or_beginning]) |
| NPV | Calculates the net present value of an investment based on a series of periodic cash flows and a discount rate. | NPV(discount, cashflow1, [cashflow2, ...]) |
| OCT2BIN | Converts a signed octal number to signed binary format. | OCT2BIN(signed_octal_number, [significant_digits]) |
| OCT2DEC | Converts a signed octal number to decimal format. | OCT2DEC(signed_octal_number) |
| OCT2HEX | Converts a signed octal number to signed hexadecimal format. | OCT2HEX(signed_octal_number, [significant_digits]) |
| ODD | Rounds a number up to the nearest odd integer. | ODD(value) |
| OR | Returns TRUE if any of the provided arguments are logically true, and FALSE if all of the provided arguments are logically false. | OR(logical_expression1, [logical_expression2, ...]) |
| PDURATION | Returns the number of periods for an investment to reach a specific value at a given rate. | PDURATION(rate, present_value, future_value) |
| PEARSON | Calculates r, the Pearson product-moment correlation coefficient of a dataset. | PEARSON(data_y, data_x) |
| PERCENTILEEXC | Returns the value at a given percentile of a dataset, exclusive of 0 and 1. | PERCENTILEEXC(data, percentile) |
| PERCENTILEINC | Returns the value at a given percentile of a dataset. | PERCENTILE.INC(data, percentile) |
| PERCENTRANKEXC | Returns the percentage rank (percentile) from 0 to 1 exclusive of a specified value in a dataset. | PERCENTRANK.EXC(data, value, [significant_digits]) |
| PERCENTRANKINC | Returns the percentage rank (percentile) from 0 to 1 inclusive of a specified value in a dataset. | PERCENTRANK.INC(data, value, [significant_digits]) |
| PERMUT | Returns the number of ways to choose some number of objects from a pool of a given size of objects, considering order. | PERMUT(n, k) |
| PERMUTATIONA | Returns the number of permutations for selecting a group of objects (with replacement) from a total number of objects. | PERMUTATIONA(number, number_chosen) |
| PHI | The PHI function returns the value of the normal distribution with mean 0 and standard deviation 1. | PHI(x) |
| PI | Returns the value of Pi to 14 decimal places. | PI() |
| PMT | Calculates the periodic payment for an annuity investment based on constant-amount periodic payments and a constant interest rate. | PMT(rate, number_of_periods, present_value, [future_value], [end_or_beginning]) |
| POISSON.DIST | Returns the value of the Poisson distribution function (or Poisson cumulative distribution function) for a specified value and mean. | POISSON.DIST(x, mean, [cumulative]) |
| POWER | Returns a number raised to a power. | POWER(base, exponent) |
| PPMT | Calculates the payment on the principal of an investment based on constant-amount periodic payments and a constant interest rate. | PPMT(rate, period, number_of_periods, present_value, [future_value], [end_or_beginning]) |
| PRODUCT | Returns the result of multiplying a series of numbers together. | PRODUCT(factor1, [factor2, ...]) |
| PROPER | Capitalizes each word in a specified string. | PROPER(text_to_capitalize) |
| PV | Calculates the present value of an annuity investment based on constant-amount periodic payments and a constant interest rate. | PV(rate, number_of_periods, payment_amount, [future_value], [end_or_beginning]) |
| QUARTILE.EXC | Returns value nearest to a given quartile of a dataset, exclusive of 0 and 4. | QUARTILE.EXC(data, quartile_number) |
| QUOTIENT | Returns one number divided by another. | QUOTIENT(dividend, divisor) |
| RADIANS | Converts an angle value in degrees to radians. | RADIANS(angle) |
| RAND | Returns a random number between 0 inclusive and 1 exclusive. | RAND() |
| RANDBETWEEN | Returns a uniformly random integer between two values, inclusive. | RANDBETWEEN(low, high) |
| RANK.AVG | Returns the rank of a specified value in a dataset. If there is more than one entry of the same value in the dataset, the average rank of the entries will be returned. | RANK.AVG(value, data, [is_ascending]) |
| RANK.EQ | Returns the rank of a specified value in a dataset. If there is more than one entry of the same value in the dataset, the top rank of the entries will be returned. | RANK.EQ(value, data, [is_ascending]) |
| RATE | Calculates the interest rate of an annuity investment based on constant-amount periodic payments and the assumption of a constant interest rate. | RATE(number_of_periods, payment_per_period, present_value, [future_value], [end_or_beginning], [rate_guess]) |
| REPLACE | Replaces part of a text string with a different text string. | REPLACE(text, position, length, new_text) |
| REPT | Returns specified text repeated a number of times. | REPT(text_to_repeat, number_of_repetitions) |
| RIGHT | Returns a substring from the end of a specified string. | RIGHT(string, [number_of_characters]) |
| ROMAN | Formats a number in Roman numerals. | ROMAN(number, [rule_relaxation]) |
| ROUND | Rounds a number to a certain number of decimal places according to standard rules. | ROUND(value, [places]) |
| ROUNDDOWN | Rounds a number to a certain number of decimal places, always rounding down to the next valid increment. | ROUNDDOWN(value, [places]) |
| ROUNDUP | Rounds a number to a certain number of decimal places, always rounding up to the next valid increment. | ROUNDUP(value, [places]) |
| ROWS | Returns the number of rows in a specified array or range. | ROWS(range) |
| RRI | Returns the interest rate needed for an investment to reach a specific value within a given number of periods. | RRI(number_of_periods, present_value, future_value) |
| RSQ | Calculates the square of r, the Pearson product-moment correlation coefficient of a dataset. | RSQ(data_y, data_x) |
| SEARCH | Returns the position at which a string is first found within text. | SEARCH(search_for, text_to_search, [starting_at]) |
| SEC | The SEC function returns the secant of an angle, measured in radians. | SEC(angle) |
| SECH | The SECH function returns the hyperbolic secant of an angle. | SECH(value) |
| SIGN | Given an input number, returns `-1` if it is negative, `1` if positive, and `0` if it is zero. | SIGN(value) |
| SIN | Returns the sine of an angle provided in radians. | SIN(angle) |
| SINH | Returns the hyperbolic sine of any real number. | SINH(value) |
| SKEW | Calculates the skewness of a dataset, which describes the symmetry of that dataset about the mean. | SKEW(value1, value2) |
| SKEW.P | Calculates the skewness of a dataset that represents the entire population. | SKEW.P(value1, value2) |
| SLN | Calculates the depreciation of an asset for one period using the straight-line method. | SLN(cost, salvage, life) |
| SLOPE | Calculates the slope of the line resulting from linear regression of a dataset. | SLOPE(data_y, data_x) |
| SMALL | Returns the nth smallest element from a data set, where n is user-defined. | SMALL(data, n) |
| SQRT | Returns the positive square root of a positive number | SQRT(value) |
| SQRTPI | Returns the positive square root of the product of Pi and the given positive number. | SQRTPI(value) |
| STANDARDIZE | Calculates the normalized equivalent of a random variable given mean and standard deviation of the distribution. | STANDARDIZE(value, mean, standard_deviation) |
| STDEV.P | Calculates the standard deviation based on an entire population. | STDEV.P(value1, [value2, ...]) |
| STDEV.S | Calculates the standard deviation based on an entire population, setting text to the value `0`. | STDEV.S(value1, [value2, ...]) |
| STDEVA | Calculates the standard deviation based on a sample, setting text to the value `0`. | STDEVA(value1, value2) |
| STDEVPA | Calculates the standard deviation based on an entire population, setting text to the value `0`. | STDEVPA(value1, value2) |
| STEYX | Calculates the standard error of the predicted y-value for each x in the regression of a dataset. | STEYX(data_y, data_x) |
| SUBSTITUTE | Replaces existing text with new text in a string. | SUBSTITUTE(text_to_search, search_for, replace_with, [occurrence_number]) |
| SUBTOTAL |
Returns a subtotal for a vertical range of cells using a specified aggregation function. |
SUBTOTAL(function_code, range1, [range2, ...]) *only support function codes 1-9 |
| SUM | Sum of series of numbers/ cells. | SUM(value1, [value2, ...]) |
| SUMIF | Returns a conditional sum across a range. | SUMIF(range, criterion, [sum_range]) |
| SUMIFS | Returns the sum of a range depending on multiple criteria. | SUMIFS(sum_range, criteria_range1, criterion1, [criteria_range2, criterion2, ...]) |
| SUMPRODUCT | Calculates the sum of the products of corresponding entries in two equal-sized arrays or ranges. | SUMPRODUCT(array1, [array2, ...]) |
| SUMSQ | Returns the sum of the squares of a series of numbers and/or cells. | SUMSQ(value1, [value2, ...]) |
| SUMX2MY2 | Calculates the sum of the differences of the squares of values in two arrays. | SUMX2MY2(array_x, array_y) |
| SUMX2PY2 | Calculates the sum of the sums of the squares of values in two arrays. | SUMX2PY2(array_x, array_y) |
| SUMXMY2 | Calculates the sum of the squares of differences of values in two arrays. | SUMXMY2(array_x, array_y) |
| SYD | Calculates the depreciation of an asset for a specified period using the sum of years digits method. | SYD(cost, salvage, life, period) |
| T | Returns string arguments as text. | T(value) |
| T.DIST | Returns the right tailed Student distribution for a value x. | T.DIST(x, degrees_freedom, cumulative) |
| T.DIST.2T | Returns the two tailed Student distribution for a value x. | T.DIST.2T(x, degrees_freedom) |
| T.DIST.RT | Returns the right tailed Student distribution for a value x. | T.DIST.RT(x, degrees_freedom) |
| T.INV | Calculates the negative inverse of the one-tailed TDIST function. | T.INV(probability, degrees_freedom) |
| T.INV.2T | Calculates the inverse of the two-tailed TDIST function. | T.INV.2T(probability, degrees_freedom) |
| TAN | Returns the tangent of an angle provided in radians. | TAN(angle) |
| TANH | Returns the hyperbolic tangent of any real number | TANH(value) |
| TODAY | Returns the current date as a date value. | TODAY() |
| TRIM | Removes leading and trailing spaces in a specified string. | TRIM(text) |
| TRIMMEAN | Calculates the mean of a dataset excluding some proportion of data from the high and low ends of the dataset. | TRIMMEAN(data, exclude_proportion) |
| TRUE | Returns the logical value `TRUE`as TRUE. | TRUE() |
| TRUNC | Truncates a number to a certain number of significant digits by omitting less significant digits. | TRUNC(value, [places]) |
| UNICHAR | Returns the Unicode character for a number. | UNICHAR(number) |
| UNICODE | Returns the decimal Unicode value of the first character of the text. | UNICODE(text) |
| UPPER | Converts a specified string to uppercase. | UPPER(text) |
| VAR.P | Calculates the variance based on an entire population | VAR.P(value1, [value2, ...]) |
| VAR.S | Calculates the variance based on a sample. | VAR.S(value1, [value2, ...]) |
| VARA | Calculates an estimate of variance based on a sample, setting text to the value `0`. | VARA(value1, value2) |
| VARPA | Calculates the variance based on an entire population, setting text to the value `0`. | VARPA(value1, value2,...) |
| VLOOKUP | Vertical lookup. Searches down the first column of a range for a key and returns the value of a specified cell in the row found. | VLOOKUP(search_key, range, index, [is_sorted]) |
| WEEKDAY | Returns a number representing the day of the week of the date provided. | WEEKDAY(date, [type]) |
| WEEKNUM | Returns a number representing the week of the year where the provided date falls. | WEEKNUM(date, [type]) |
| WEIBULL.DIST | Returns the value of the Weibull distribution function (or Weibull cumulative distribution function) for a specified shape and scale. | WEIBULL.DIST(x, shape, scale, cumulative) |
| WORKDAY | Calculates the end date after a specified number of working days. | WORKDAY(start_date, num_days, [holidays]) |
| XIRR | Calculates the internal rate of return of an investment based on a specified series of potentially irregularly spaced cash flows. | XIRR(cashflow_amounts, cashflow_dates, [rate_guess]) |
| XNPV | Calculates the net present value of an investment based on a specified series of potentially irregularly spaced cash flows and a discount rate. | XNPV(discount, cashflow_amounts, cashflow_dates) |
| XOR | The XOR function performs an exclusive or of 2 numbers that returns a TRUE if the numbers are different, and a FALSE otherwise. | XOR(logical_expression1, [logical_expression2, ...]) |
| YEAR | Returns the year specified by a given date. | YEAR(date) |
| YEARFRAC | Returns the number of years, including fractional years, between two dates using a specified day count convention. | YEARFRAC(start_date, end_date, [day_count_convention]) |